
Summary of research and developments
Structural and algorithmic organization of random arcs and sectors generation devices in the 3D space for volumetric displays
Preface
Nowadays the displaying devices are the main means of human and machines interconnection. Information becomes available for machine exactly after data processing in displaying device. Information output and providing algorithms are enough studied and researched concepts. Displaying of alphanumeric objects is oriented on language commutativity providing. But displaying of data and information using natural and artificial graphical images became the main method of large informational packages displaying. This information is processed by the humans visual centers and eyes. They get, pass and process the largest volume of information that comes to human brain [1].
The development of new construction methods and approaches of 3D information displaying devices, so called 3D displays, gives the acceleration to new researches in volumetric visualization area. These researches are closely connected to creation of algorithmic base of graphical objects generation and output of voxelized objects and scenes. It should be noted that in literary sources [3] the aspects that are connected to creation of voxel models (voxelization) of real objects are considered in details (for example the process of voxelization using 3D scanners). At the same time the principles and algorithms of graphic primitives generation are not considered.
Informativity increasing and improvement of visual capabilities of data transmission visual channel between human and machines leads us to creation of three-dimensional displays. Modern classification [2] of 3D displaying devices separates special branch of systems that are built using the means of volumetric technologies. These devices provide the creation of virtual images and objects in 3D space. By the way the volumetric effect is provided for set of observers that are located in a wide range both vertically and horizontally.
Specialized hardware and software means are necessary and important for creation and using of these devices. Availability of volumetric voxel storage memory (analog of rasterization memory in 2D displaying devices) is feature of displaying devices that are based on volumetric technologies. Voxelized models of real objects are created during the generation process of 3D image in voxel memory by means of software. These models consist of three-dimensional graphic primitives such as parts of straight lines, thee-dimensional plains, arcs, circles, spheres and ellipses [1].
Topicality
Because of steady hardware power increase which is intended to data processing and providing of visual information to human we see the demand increase which is dedicated to development of effective graphic primitives generation algorithms. Later these primitives form more complex graphic objects and their compositions which will be used during the process of complex scenes construction. After that these scenes will be displayed in space of volumetric displaying devices.
It is well known that there are many methods and approaches that are dedicated to displaying process acceleration in the screen of displaying device. Algorithms that describe the visualization process are well debugged and tested concepts. But the majority of well known algorithms and approaches are oriented to problems that are closely connected to visualization of information in space of well known to every user displaying devices such as monitors, plotters, running lines and others. Visualization process by means of volumetric displays is more restricted area. The problems that should be solved by developer are the complexity of accurate, high qualitative and effective generation algorithms development, complexity of error checking that are unavoidable during the development process, high cost of hardware that can help during the research process and others. That is why time after time every developer should use nontrivial approaches. One of these approaches is using of software that can substitute real three-dimensional displays. It is impossible to forget about software packages like MatLab, MathCAD, ScIDAVis, 3D-grapher that display the part of real uninterrupted Euclidean space. Also it is possible to develop our own software that can substitute three-dimensional displaying device.
But it is only incomplete list of problems that are connected to generation algorithms error checking in space of three-dimensional displaying devices. The debugging and testing processes are so complicated too. If we compare 2D and 3D generation algorithms we should make the decision that 3D mathematical tools are more complicated. Every time we need to develop 3D graphic algorithm it is necessary to understand that the time and hardware optimization process is so important too.
Overview
I should say that voxel graphics is not new approach in computer area. There are many articles in World Wide Web that are closely connected to voxel graphics applications. In these articles their authors consider the problems and applications of voxel graphics.
1. Vincent Breton in his article consideres applications of voxel graphics in medicine during the diagnostics process. In Russian.
2. Zabugorsky N. in his article consideres the aspects that are connected to computer games development process. In Russian.
3. Shalamov А.V. and Mazein P.G. consider voxel graphics as an application for popular CAD systems. In Russian.
But specialized researches that are dedicated to graphic primitives generation in space of three-dimensional displaying devices [4, 5, 6] are rather scantily explored area.
1. Baskkov Е.А., Avksentieva O.A., Al-Oraiqat Anas М. in their article consider the methods of graphic primitives construction in space of three-dimensional displays. In Russian.
2. Bashkov Е.А., Avksentieva O.A., Al-Oraiqat Anas М., Hlopov D.I. in their article consider the graphic primitives generation methods. Also they consider the methods of their generation process acceleration. In Russian.
3. Bashkov Е.А., Avksentieva O.A., Al-Oraiqat Anas М., Dubrovina О.D. in their article consider algorithmic base which is connected to construction of straight line parts for 3D displays. In Russian.
The search on the masters portal gave me some links to masters abstracts and articles which are dedicated to the problems and methods of voxel graphics.
1. Master Hromova Е.N. considers the problem of net model creation of object with complex shape using the random set of points in 3D space. In Russian.
2. Master Zaharov S.S. considers the problem of natural phenomenon computer modeling and sky and clouds construction. In Russian.
2. Master Zaharov S.S. considers the problem of natural phenomenon computer modeling and sky and clouds construction. In Russian.
Aims and tasks
It was decided to create and develop optimal, effective and accurate generation algorithm of volumetric spline in three-dimensional space. But the main problem was to determine the methods of its development, testing and debugging [7]. It was decided to research the following branches:
1. To research an optimal arc generation algorithm. This volumetric arc is considered as graphical primitive in space of 3D displaying device. To find the set of coordinates of each voxel which participates in given graphic primitive voxel decomposition.
2. To research and develop the evaluating criteria for voxel decomposition and its time delay. Also it was decided to develop the optimization criteria for obtained parameters.
3. To test obtained algorithm using the random values. There were some cyclic attempts that helped to evaluate obtained values and results.
4. To test obtained algorithm using various hardware architectures and platforms. Also it is necessary to obtain the results and characteristics that point to program duration and accuracy of developed algorithm.
5. To make the decision using the results of different platforms.
6. To make an attempt to construct more complex graphic primitive which is based on already developed and tested arc generation algorithm in space of three-dimensional displaying device. For example to find the set of voxel coordinates. All of these voxels participate in voxel decomposition of sphere or ellipse. The earlier attempts were focused on geometric object construction. The form of this object was similar to half-pipe with random angle of generation along the straight line. Later it was attempt to construct a part of sphere which was set by three its points.
Scientific innovation
During the research process the methods of graphic primitive (arc) generation were developed. The set of voxel coordinates that form the voxel decomposition of given primitive was built. Also the optimization methods for obtained algorithm were proposed. First branch of proposed improvements is dedicated to algorithm time duration optimization process. This branch consists of improvements that change the code of obtained program. Also it is necessary to say about software-hardware improvements that are dedicated to CUDA architecture applying. This applying considers GPU as calculation resource. Also GPU was applied as parallel platform that gives us an opportunity to use GPU as powerful calculation system. Also it is necessary to say about hardware improvements that were proposed. During the development process it was decided to use Xilinx [8, 9] FPGA to test developed algorithm from the point of view of hardware realization. Eventually an obtained algorithm has been tested from the point of view of different platforms and architectures.
Experimental facilities
1. Software method of optimization was mostly dedicated to the program code changes. Improved program has been tested using multiple launches. After every launch cycle its results were analyzed. Also time duration and accuracy characteristics have been analyzed too. An obtained program was tested on personal computer which has such power characteristics: Intel(R) Celeron CPU 2.3GHz, 1 Gb RAM.
2. Using of CUDA architecture as high-speed calculation system caused the software-hardware branch of algorithm optimization. First of all I should say that software changes consisted of direct code changes. The parts of program that could be executed in parallel were changed according to the CUDA restrictions and requirements. All the experiments that were dedicated to parallel realization of obtained algorithm have been done using personal computer with such power characteristics: Intel(R) Core(TM)2 Duo CPU E4600 2.40GHz, 1,99Gb RAM.
3. Hardware branch of algorithm optimization consisted of program loading into Xilinx FPGA. All the time duration and accuracy characteristics have been analyzed using multiple launches technique. Finally an attempt to construct specialized hardware algorithm realization have been done successfully. The main task of research process has been completed. All its branches were completed successfully too.
Figure 1 explains the steps of generation algorithm development and testing process.

Figure 1 — Steps of research process during construction of graphic primitive generation algorithm
5 frames. Last frame delay time = 2 sec. Other frames delay time = 1 sec.
Animation size: 382px х 240px. File size: 29.7 Kbytes. Created using Adobe ImageReady.
Basic algorithm overview. Software problem solution
The following 2D graphic primitives generation algorithms were considered during the research process:
1. DDA (Digital Differential Analyzer) algorithm .
2. 2D Bresenham's cycle and strainght line generation algorithms.
3. 3D Bresenham's straight line generation algorithm.
After studying of already tested and developed algorithm base it was decided to develop new algorithm which takes into account positive and negative features of described approaches. The main aim of arc rasterization is to obtain the set of voxels that are located in space of three-dimensional displaying device and all of them have the minimal distance to real arc. Also it is necessary to say about such situation when all of the voxels (except first and last voxels in decomposition) have only two neighboring voxels. Amount of floating-point calculations has been reduced to the limit because classical 2D Bresenham's algorithm operates only with integer values and numbers. Total reduction of floating-point calculations is impossible because 3D algorithm of spline generation must operate with essential amount of floating-point numbers and values. The main idea of obtained program is to input initial data (start point of generation, end point of generation, point in plane of generation, angle of arc) into its main function and pass the following steps:
1. To obtain, test and process initial data. To calculate plain equation coefficients [10]. To convert initial floating-point values into integer values using ceil() function.
2. To calculate an end point of 3D spline using the rotation matrix.
3. Cyclic consistently calculation of all voxel coordinates that form voxel decomposition. Each voxel has 7 neighboring voxels. Each of these neighboring voxels can be the next point in voxel decomposition. There are two quantitative characteristics are calculated for each voxel during every step of algorithm. The result of these two characteristics processing is the number of next voxel in decomposition.
4. Also the qualitatively characteristics are calculated during each step of algorithm. They point to accuracy and time delay of obtained algorithm calculations. After the calculation process all of these characteristics would be summarized and analyzed.
Developed algorithm could be represented using pseudo-language from [11] by following set of statements:
Arc voxelization algorithm
Input data: starting arc point N, central arc point C, point in the plane P, α arc angle.
Output data: array of voxels V
Begin
Input C, P, N, α; Determination of VC, VP, VN Calculation of CP and CN vectors coordinates Calculation of n vector Calculation of arc radius K point coordinates calculation Repeat Calculation of k vector Formation of priority matrix M Do k = 1,2 … 7 V(k)<q+1>:= VN + M(k) +0.5 Error E1(k)<q+1> calculation Error E2(k)<q+1> calculation End Do
MIN = MIN(E1(k)<q+1> + E2(k)<q+1>))
Do k = 1,2 … 7
If (E1(k)<q+1> = MIN)
If (MAX priority)
Vpoints:= VN + M(k)
points:= points + 1
End if
End if
End Do
Until VN<>VK
Output V
End
Modified and optimized version of algorithm was tested using multiple launches. The amount of launches varied from 10 to 10 000. Also it is important to say that internal data initialization algorithm used pseudo-random generator during the initialization process. The result of 1 000 launches is shown below:
Amount of arcs = 1000 Amount of voxels = 1949224 Summary E1 = 435864.58976 Summary E2 = 433187.11029 Summary E3 = 696534.57655 ============================================================== Average radius error (E1av) = 0.22361 Average distance to plain error (E2av) = 0.22224 Average distance to function (E3av) = 0.35734 ============================================================== MAX radius error (E1max) = 0.84506 MAX distance to plain error (E2max) = 0.84604 MAX distance to function (E3max) = 0.86601 ============================================================== MIN radius error (E1min) = 0.00010 MIN distance to plain error (E2min) = 0.00000 MIN distance to function (E3min) = 0.00016 Time delay for 1 000 arcs = 20593 ms
The result of program execution is shown below. Calculated set of voxel coordinates have been wrote to text file which had special structure. After this the set of obtained voxels could be processed using 3D visualization program. Matlab 7.01 had been used to display the set of voxels in part of Euclidean space which is displayed by three-dimensional displaying device.
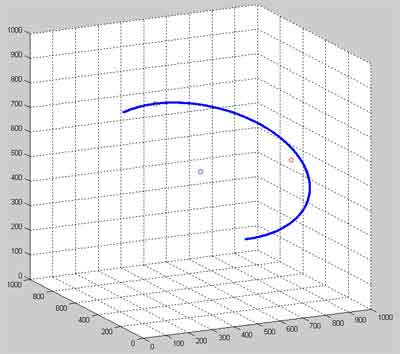
Figure 2 — The result of visualization of three-dimensional arc which is initialized by random parameters
(visualization environment – MatLab 7.01 software package)
Further improvements using CUDA
«CUDA (an acronym for Compute Unified Device Architecture) is a parallel computing architecture developed by NVIDIA. CUDA is the computing engine in NVIDIA graphics processing units (GPUs) that is accessible to software developers through variants of industry standard programming languages. Programmers use 'C for CUDA' (C with NVIDIA extensions and certain restrictions), compiled through a PathScale Open64 C compiler, to code algorithms for execution on the GPU. CUDA architecture shares a range of computational interfaces with two competitors - the Khronos Group's Open Computing Language and Microsoft's DirectCompute. Third party wrappers are also available for Python, Perl, Fortran, Java, Ruby, Lua, MATLAB and IDL, and native support exists in Mathematica.
CUDA gives developers access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs. Using CUDA, the latest NVIDIA GPUs become accessible for computation like CPUs. Unlike CPUs however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly. This approach of solving general purpose problems on GPUs is known as GPGPU.» [12]
During software-hardware optimization process CUDA architecture had been used as high-speed parallel system which can execute parts of developed code in parallel. As we can modify our code which is written using standard C language according to CUDA restrictions and requirements [14, 15] obtained algorithm had been translated to special C language dialect. There were some complexities during program development which were dedicated to searching of code blocks that could be translated to parallel language [16, 17]. These blocks had been found and realized taking into account cycles amount minimization.
When program is developed taking into account CUDA’s restrictions and requirements its debugging process is the main problem for program tester and developer. This complexity is closely connected to impossibility to use standard Microsoft Visual Studio Debugger. All the parameters that are passed into CUDA function are unavailable to see their content because they are placed in internal GPU memory. In this case the standard approach to solve this problem is to show the value of variable in the screen. But CUDA function has no access to output streams or files. It was decided to use step-by-step copying of internal GPU data to CPU memory. This method also requires special program code adaptation. It is necessary to say that this method is so inconvenient because time delay essentially increases. One of the requirements to effective CUDA code is minimization of data transfer between GPU and CPU. Because of this it was decided to refuse from this approach.
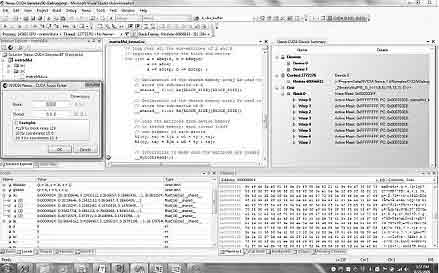
Figure 3 — Nexus Debug Environment
Because the developed program describes nontrivial algorithm it was necessary to find effective method which could help to debug a program. Using of nVidia Nexus helped to debug this algorithm. The parallel CUDA programming process accelerated when nVidia Nexus technology had been embedded into Microsoft Visual Studio. As we see in [18, 19] the main opportunities that are available in Nexus to every developer are:
One of the main tasks that appeared during program development was to find the method which could help to calculate programs time duration. Standard getTickCount() function showed incorrect results and it was decided to refuse from its using. Standard CUDA architecture method Compute Visual Profiler became the most comfortable method of programs time delay calculation. The values obtained using Compute Visual Profiler are given in table 1.
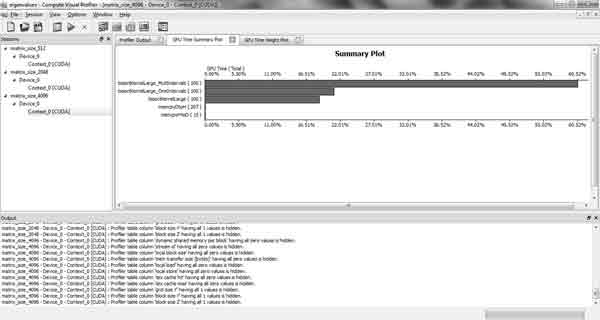
Figure 4 — CUDA Compute Visual Profiler
CUDA architecture showed very good results. As I increased an amount of cycles to test arc generation application the degree of parallelism increased too. According to amount of testing launches an acceleration which had been shown by CUDA was from 4.5 up to 8.7 times. These results were predictable because the degree of parallelism was equal to amount of neighboring voxels for each voxel. So the calculation of next voxel coordinates in voxel decomposition had been done in parallel.
Table 1 — CPU and GPU time duration comparative analysis
| Amount of cycles | CPU (msec) | GPU (msec) | GPU and CPU calculation time ration |
| 128 | 328 | 73,559 | 4,459005696 |
| 512 | 1297 | 187,437 | 6,919658339 |
| 1024 | 2641 | 359,803 | 7,340127792 |
| 4096 | 10172 | 1254,01 | 8,111578058 |
| 10240 | 25547 | 2990,54 | 8,542604346 |
| 16384 | 41672 | 4785,61 | 8,707771841 |
From CUDA to FPGA
«That it is one rule that specialized devices that are used in particular area are always faster than universal devices. This rule becomes true independently of technical tricks because the aim of special device construction is to accelerate calculation process using specialized hardware. In other words the specialized devices are constructed to be better than universal devices». [10]
This phrase became the main accelerator during hardware improvements. An attempt to construct and test specialized device using Xilinx FPGA had been done to decrease time delay of developed algorithm. It was decided to compare all of the optimization methods to identify the best method to optimize similar algorithms.

Figure 5 — Xilinx Spartan-3E FPGA
The main aims of Xilinx FPGA loading according to graphic primitive generation algorithm were such approaches:
1. Loading of initial data into FPGA using its interface.
2. Multiple tests of algorithm to find errors and inaccuracies.
3. Testing of algorithm on FPGA to obtain output of results.
4. Time delay analysis. Also I should analyze accuracy characteristics of developed algorithm.
Practical results
When I wrote my masters research report the research process was not only theoretical procedure. All of the practical results are confirmed from the point of view of software, software-hardware and hardware levels of algorithm improvements. The following stages had been passed by algorithm during research process:
1. Main task formulation.
2. Algorithm base research.
3. Quantitative and qualitative criteria development.
4. Optimization of algorithm from the point of view of decreasing of floating-point values usage. Testing of algorithm using CPU, calculation of time delay and occuracy characteristics.
5. Optimization of algorithm according to CUDA restrictions and requirements. Testing of algorithm using GPU and CPU, calculation of time delay and occuracy characteristics.
6. Creation of algorithm for further FPGA loading. Testing of algorithm using hardware, calculation of time delay and occuracy characteristics.
Conclusion
My experience received during research process shows that every idea could be implemented using high spectrum of possibilities. Every idea could pass the way from its creation up to its practical implementation using various platforms and architectures.
Links
1. Bashkov Е.А., Avksentieva O.A., Al-Oraiqat Anas М. About three-dimensional graphic primitives generator in space of 3D displays [Text]. In digest Scientific works of Donetsk National Technical University, series "Problems of modeling and design automation for dynamical systems". Issue 7 (150). - Donetsk, DonNTU. - 2008 .- pp. 203-214. In Ukrainian.
2. Favalora G.E., Volumetric 3D Displays and Application Infrastructure [Text] // "Computer", 2005, August, pp 37- 44.
3. Rogers D. Algorithmic foundations of computer graphics [Text] — Moscow.: «World», 1989. — 512 p. In Russian
4. Bashkov Е.А., Avksentieva O.A., Al-Oraiqat Anas М., Hlopov D.I. Improved straight lines generator for three-dimensional displays [Web source]. In Russian
http://www.nbuv.gov.ua/portal/natural/Npdntu_ikot/2010_11/3_1.pdf
5. Milutin M.O., Bashkov Е.А., Avksentieva O.A. Al-Oraiqat Anas М. In Russian. Arc generation algorithm for 3D displays [Text]. Donetsk, DonNTU. - 2009. In Russian
6. Avksentieva O.A., Al-Oraiqat Anas М., Hlopov D.I. Straight lines generation improved algorithm for three-dimensional displays [Text]. Materials 14. 10th international youth forum «Radioelectronics and youth in 21st century», March 18-20, 2010, Kharkov 2010, Materials digest 4.1. – Kharkov: KNURE. 2010. – 527p. In Russian.
7. Druginin A.I., Vikhman V.V. Computer graphics algorithms. Manual [Text] – Novosibirsk: NGTU Publishing office, 2003. – 47 p. In Russian.
8. Spartan-3E FPGA Family: Data Sheet [Web source]
http://www.xilinx.com/support/documentation/data_sheets/ds312.pdf
9. Spartan-3E Starter Kit Board User Guide [Web source]
http://www.digilentinc.com/Data/Products/S3EBOARD/S3EStarter_ug230.pdf
10. Beklemishev D.V. Course of analytical geometry and linear algebra [Text]. М.: Science, 1980. In Russian.
11. Preparata F., Sheimos М. Computational Geometry. Basics [Text] – М.: World, 1989. 478 p. In Russian
12. Wikipedia article about CUDA [Web source]
13. Anrew Zubinsky. NVIDIA Cuda: unification of graphics and computing [Web source]. In Russian.
14. Antonio Tumeo. Politecnico di Milano. Massively Parallel Computing with CUDA [Web source]
http://www.ogf.org/OGF25/materials/1605/CUDA_Programming.pdf
15. Nvidia CUDA Development Tools. Getting started [Web source]
http://www2.engr.arizona.edu/~ece569a/Readings/NVIDIA_Resources/QuickStart%20Guide.pdf
16. Nvidia CUDA Programming Guide [Web source]
http://developer.download.nvidia.com/compute/cuda/3_0/toolkit/docs/NVIDIA_CUDA_ProgrammingGuide.pdf
17. Nvidia CUDA Reference Manual [Web source]
http://developer.download.nvidia.com/compute/cuda/2_3/toolkit/docs/CUDA_Reference_Manual_2.3.pdf
18. dimson3d. Introducing NVIDIA CUDA, parallel computing using GPU in CG [Web source]
http://www.render.ru/books/show_book.php?book_id=840&start=1
19. Nvidia Corporation. CUDA: new architucture for GPU computing [Web source]
http://www.nvidia.ru/content/cudazone/download/ru/CUDA_for_games.pdf